Table of Contents
Aufbau einer entwicklungs-begleitenden Software-Qualitätssicherung
In meiner Zeit als Software-Entwickler bei mgm technology partners und der e.solutions GmbH durfte ich zweimal eine entwicklungsbegleitende Qualitätssicherung aufbauen.
Bei mgm technology partners konnten wir im ERiC (Elster Rich Client) die Neufehlerrate pro Release um 90% senken. Bei e.solutions begleiteten wir das Audi Virtual Cockpit in die drei ersten SOPs (Start of Production) on time und on quality für den TT3, den A4 B9 und den Q7NF.
In beiden Fällen handelte es sich um bereits laufende Projekte (brown field) und wir mussten die QS on the fly etablieren. Deswegen konnten wir nicht einfach mit “good practices” von Beginn an arbeiten, sondern sind nach dem Konzept der emerging practices vorgegangen. Maßnahmen wurden stets in enger Abstimmung mit Projektleitung und der Entwicklung definiert und eingeführt.
Grundannahmen
Für den Erfolg der Umsetzung einer “Entwicklungsbegleitende QS” waren folgende Grundsätze verantwortlich:
Sparringpartner
Die “Entwicklungsbegleitende QS” ist der Sparringspartner der Entwicklung. Die Entwickler steigen in den Ring und boxen die Feature in die Software, die EB-QS trainiert mit den Entwicklern und hält die Standards hoch: Qualität der Kunden-Anforderungen, Qualität der Fehlertickets, Qualität der Implementierung und Dokumentation.
Augenhöhe
Dies kann nur gelingen, wenn Entwicklung und QS auf gleicher Augenhöhe kommunizieren. Idealerweise existiert eine räumliche Nähe zum Entwicklungsteam (#co-locatedteams) zumindest in den ersten Monaten des Aufbaus.
Gleiche Sprache
Entwickler und Tester müssen die gleichen Werkzeuge benutzen und sollten idealerweise die gleiche(n) Sprache(n) sprechen. Dafür benötige ich spezielle Kolleg:Innen,
Google’s Rolle des “Software Developer Engineer in Tests” – Ein Software-Entwickler, der die Brille eines Testers aufsetzt trifft den benötigen Typus sehr gut.
Die EB-QS muss die Entwickler antreiben. Nicht andersherum. Wenn der Entwickler entscheidet, wann was wie getestet wird, ist das Konzept zum Scheitern verurteilt.
Issue-Management
Das Issue-Management ist der Dreh- und Angelpunkt jeder erfolgreichen Software-Entwicklung. Defizite in diesem Bereich holen einen früher oder später wieder ein.
Demzufolge sollte die EB-QS darauf drängen, das System intensiv zu nutzen und mit gutem Beispiel vorangehen.
Was soll alles im Issue Management verwaltet werden?
tl;dr; Alles!
- Anforderungen des Kunden
- Die aus den Anforderungen abgeleiteten Arbeitspakete
- Fehler, die vom Kunden gemeldet werden
- Intern entdeckte Fehler
- Verbesserungsmaßnahmen / Refactorings
- Die Release-Planung
- Die Testplanung
Warum ist es so wichtig, alles in ein einziges IM einzupflegen?
- Vermeidung von Medienbrüchen
- Definition einheitlicher Workflows
- Globale Zeitplanung möglich
- Auslastung der MA sichtbar
Quick Wins – Ramp-Up-Zeiten durch Einsatz eines Wiki minimieren
Qualität ist alles was das Produkt besser macht. Und je mehr Zeit ein Entwickler in das Produkt investieren kann, desto höher ist die Chance, dass das Produkt auch tatsächlich besser wird.
(Refactorings werden oft aus Zeitgründen “verschoben”)
In der Praxis muss der Entwickler sich um wesentlich mehr kümmern als nur ums Coden. Hinderlich sind oft ein komplexes Buildsystem, das undurchschaubare Managen von Abhängigkeiten, schwierige Deployments etc.
Gerade wenn ein Entwickler neu in ein Projekt kommt, wird er knallhart mit dem historisch gewachsenen Dschungel an Dos and Don’ts konfrontiert.
Die Einarbeitungszeit kann leicht von mehreren Tagen bis Wochen gehen, je nachdem wie komplex das Projekt ist.
Wie kann man nun pragmatisch Licht ins Dunkel bringen, bzw. das Dschungel-Dickicht durchdringen?
Als erste Maßnahme sollte ein Konsens darüber bestehen, welche Schritte notwendig sind, um ein Software-Projekt auf die Festplatte und übersetzt zu bekommen.
Fragt man drei Entwickler, wie das genau geht, bekommt man 4 Antworten.
Oft entsteht auch ein Disput darüber, welche Tools, Zugriffsrechte und Schritte wirklich notwendig sind und was nur wider besseren Wissens redundant ausgeführt wird.
Das Team sollte das Vorgehen auf einer Wiki-Seite hinterlegen und schrittweise verfeinern.
Ideal ist es natürlich, wenn in regelmäßigen Abständen neue Leute ins Team kommen, die quasi als noch Außenstehende die Anleitungen benutzen und dabei verifizieren und verbessern.
Allein durch das systematische Erfassen aller zum Entwickeln benötigten Tools, Zugriffsberechtigungen, Reihenfolge der Installation konnte die Onboarding der Tester und auch Entwickler von mehreren Wochen auf wenige Tage reduziert werden.
(Das Nachvollziehen technischer Aspekte wie Anforderungen und Implementierung ist ein aufwendigerer Prozess. Jedoch sollte auch dafür der Einstieg über das Wiki erleichtert werden. Wir haben eine “Feature Design Spec” definiert, die grob pro Feature geltende Lastenhefte sowie betroffene Module und Komponenten bündelt)
Diese Ramp-Up-Zeit kann natürlich weiter optimiert werden, in dem die Vorgehensweise reflektiert werden.
Einige Idee
- Vorgaben bezüglich der im Team unterstützter Tools. Muss es wirklich noch Eclipse sein?
- Dokumentation von Entscheidungsprozessen (bspw. warum verzichten wir auf RTTI?)
- Team Capability Matrix (Wer kann was)
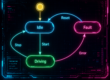
Quality Stack
Die Qualität von Software lässt sich am Besten mit Hilfe des Qualitäts-Stack betrachten:
Am oberen Ende steht die Überprüfung der funktionalen Anforderungen, am unteren Ende die rein technische Funktionalität. Lapidar, der Code lässt sich aus der Versionsverwaltung auschecken und baut.
Die einzelnen Stufen des Stacks stehen für unterschiedliche Fehlermöglichkeiten. Von unten nach oben:
- Checkout
- Die erste Hürde, die ein Entwickler nehmen muss, um mit dem Quellcode zu arbeiten, ist das Auschecken aus dem Repository.
- Compiler
- Klar, Code der syntaktisch falsch ist, wird vom Compiler nicht übersetzt.
- Zudem liefert der Compiler über verschiedene Warn-Levels erste semantische Fehler (Narrowing von Datentypen)
- Statische Analyse
- Auf der Stufe der statischen Code-Analyse werden semantische Fehler offensichtlich, die auf die korrekte Benutzung von Bibliotheken abzielen.
Auch coding conventions können hier überprüft werden
- Auf der Stufe der statischen Code-Analyse werden semantische Fehler offensichtlich, die auf die korrekte Benutzung von Bibliotheken abzielen.
- Unit-Tests
- testen funktionale Requirements auf Klassen-Ebene
- Deployment
- bringt das SW-Produkt auf die Zielplattform (embedded system, App, Servlet)
- Dynamische Analyse
- zielt ab auf das Laufzeitverhalten der SW z.B. das Auftreten von Memory Leaks
- Funktionstests (Integration / End-to-End)
- dienen der Verifikation von funktionalen Anforderungen
- Performance-Tests
- testen nicht-funktionale Anforderungen wie Round-Trip-Zeiten
- Startup-Tests
- Smoke-Test / Minimum Acceptance Test
- testet das Deployment und die wesentlichsten funktionalen Anforderungen
- Sonderstellung im Q-Stack
Continous Integration
Als Rahmen für die Abbildung des gesamten Q-Stack dient der Einsatz eines so genannten Continous Integration Systems (CI).
Da es aus zeitlichen Gründen nicht sinnvoll ist, jeden Entwickler bei jeder Änderung alle Tests und Analysen auf allen Ebenen des Q-Stacks auf seiner Maschine ausführen zu lassen, überlässt man diese Aufgabe einer separaten Build-Maschine.
Durch eine geeignete Konfiguration von Jobs lassen sich die einzelnen Stufen des Stacks automatisieren und schedulen, so dass sich immer ein aktuelles Bild des Gesundheitszustands der Software ergibt.
Als Faustformel kann man sagen, je höher im Stack, desto seltener können / müssen die Tests ausgeführt werden, da der Ressourcenverbrauch steigt. (Deployment, DB-Update vor Tests)
In der Praxis eignet sich ein als sanity check ein CI-Job alle 15 Minuten, der den Code auscheckt, baut und evtl die Unit-Tests ausführt. Die meisten modernen Code-Repos unterstützen commit hooks, sodass nicht gepollt werden muss, sondern der Build vom RCS getriggert wird.
In einem nightly build werden dann alle weiteren Analysen durchgeführt und stehen am nächsten Tag zur Verfügung. (Startzeit nach 22 Uhr oder später / nach Geschäftsschluss)
Dazu eignet sich ein cron job oder @midnight im Jenkins
Es kommen in zunehmender Zahl auch sog. Quality Dashboards / Server wie sonarqube auf den Markt, die verschiedene Analysewerkzeuge bündeln (findbugs, pmd, cobertura) und mit einem sinnvollen Set an Regeln parametrieren und einem somit viel Arbeit ersparen.
Durch Integration via Plugins in die CI kommt man schnell zu einem umfassenden Bild der SW-Qualität.
Quick Wins – Manueller Smoketest
Ein manueller Smoketest vor jedem Release geht schnell und bringt viel. Wenn alle bisher aufgetretenen Fehler im Issue Management erfasst wurden, können wir uns nun an die Erstellung eines Smoketest-Plans machen.
Beginnend mit den schwerwiegendsten Fehlern erstellen wir eine Liste und definieren zu jedem Fehler eine Möglichkeit zur Überprüfung, ob der Fehler im aktuellen Release noch auftritt.
| Testcase | Test Steps | Expected Result | Status | Issues |
|---|---|---|---|---|
| App Icon | Suche App im Launcher | App Icon vorhanden | ||
| Splash Screen | Starte App | Splash Screen vorhanden |
Je nach aktueller Lage wird die Liste kürzer oder länger ausfallen. Dass es sich hier um manuelle Prüfschritte handelt, ist vorerst nachrangig, weil wir nach und nach automatisierte Tests einführen werden.
Die Liste ist erst mal ein Notfallplan und dient dem Tester dazu, die blinden Flecken in der QS aufzuzeigen.
Wenn die Liste länger wird, sollte ein Status “Nicht durchgeführt” hinzukommen; auch die Einführung von Testcase-Prios kann nützlich sein, um in der Eile die wichtigsten Testfälle schnell identifizieren zu können.
Die Liste sollte in Absprache mit dem Projektleiter erstellt werden, um sicherzustellen, dass keine Fehlervorgänge fehlen, bzw die Fehler-Prioritäten richtig eingestellt sind.
(Die Prio eines Fehlers ist blickwinkelabhängig; es sollte im Projekt einen Konsens, wann welche Fehler welche Prios bekommen. Entwickler neigen dazu Fehler hochprior einzustufen, wenn die Behebung schwierig wird. Den Kunden interessiert aber, inwiefern ihn der Fehler bei der Benutzung einschränkt)
Nach jedem ausgelieferten Release sollten neue Fehler analysiert werden und in die Tabelle aufgenommen werden. Redundante Tests werden ausgemistet und Beschreibungen verbessert.
Die Zeit nach dem Release muss dann auch für die (Teil-)Automatisierung der manuellen Testschritte genutzt werden. Hierbei sollten zeitaufwändige Tests als erstes angegangen werden. Darum ist es sinnvoll im Smoke-Testplan auch die Zeiten für die Durchführung zu erfassen.
Gute Testfälle schreiben
7 +/- 2-Regel: Ein Testfall sollte zwischen 5 und 9 Testschritte beinhalten.
Orthogonalität: Unabhängigkeit von anderen Testfällen
Quick Wins – Interne Zwischen-Releases
Eine signifikante Erhöhung der Code-Qualität kann durch die Einführung von internen Zwischenreleases erreicht werden.
Angenommen der Kunde erhält alle 6 Wochen eine neue Version, dann könnte im ersten Schritt die Zeit halbiert werden und alle drei Wochen ein internes Release für die QS bereitgestellt werden.
Der Vorteil dieser Vorgehensweise liegt darin, dass die Entwickler nach dem Finden von Fehlern noch 2-3 Wochen Zeit haben, diese Fehler zu beheben.
Zudem kann die Zeit, die für das Erstellen der von Releases notwendig ist optimiert werden, bzw. neue Kollegen können mit dem Vorgehen vertraut gemacht werden, ohne den Druck eines echten Releases.
Quick Wins – Verifikationstests in 3 Phasen
Der erste Schritt zur echten entwicklungsbegleitenden QS ist die Durchführung von zeitnahen Verifikationstests.
D.h., es wird nicht gewartet, bis das nächste Release ansteht, sondern der Fehler wird nach Behebung und Code-Review verifiziert.
Dieses Vorgehen hat den Vorteil, dass der Tester im Vorfeld genügend Zeit hat, sich geeignete Testmaßnahmen zu überlegen und ggf. Tools oder Testfälle (auf Funktionstest-Level) zu schreiben.
Organisatorisch sollte der Verifikationstestablauf im Issue-Management verankert sein, d.h. wenn Fix und Review erledigt sind, sollte der Vorgang an den Tester übergeben werden.
(Neues Feld Tester für Vorgang anlegen)
Wichtig ist, dass im Ticket auch die Code-Änderung referenziert wird bspw. durch Angabe einer Changelist oder eines Patches. Spätestens beim Peer Review / Code Review wird dieses Angabe benötigt.
Durch die Referenz auf die Code-Änderung kann eine selektive Integration und ein Test dieser Änderung durchgeführt werden.
Quick Wins – One Click Build
One Click Build bedeutet einen SW-Stand mit sprichwörtlich einem Klick zu bauen. Es sollte nach dem Bauprozess das fertige, vom Kunde verwendbare Produkt entstanden sein.
Je nach Produkt sollte also ein Installer, ein Executable, ein Flash-Image oder eine library (.so / .dll / .jar) herauspurzeln.
Warum ist es wichtig, dass dies mit einem Klick passiert?
Menschen machen (in der Eile) Fehler
Menschen vergessen, welche Schritte in welcher Reihenfolge durchgeführt werden müssen.
Historie
Im Unix/Linux-Bereich hat sich der Ablauf “configure – make – make install” als Standard etabliert, um vom Quellcode zu einem funktionierenden Programm zu kommen.
So weit so gut. Meistens ist es jedoch nicht so einfach.
Ein Entwickler baut den Code gerne in der debug-Variante, der Kunde bekommt jedoch einen release-Build.
Es gibt nicht ein Produkt, sondern mehrere Varianten, mit unterschiedlichen Konfigurationen zur Compile-Zeit (Community-Edition, Professional-Edition, etc.)
Man benötigt zusätzliche Compiler-Optionen bspw. Optimize for size / speed
Das Produkt muss für mehrere Zielplattformen / HW übersetzt werden (App-Entwicklung)
Manchmal will man einen clean build manchmal nur einen inkrementellen Build
Manchmal möchte man den Build multithreaded anstoßen, manchmal single-threaded
Schon hat man über ein Dutzend Varianten ein und desselben Produktes.
Um dann noch reproduzierbare Ergebnisse zu erhalten, ist es sinnvoll alle zulässigen Kombination als eine Art “Build-Session” abzulegen und mit einem Klick zu übersetzen.
Was kann man tun?
Wir brauchen ein Build-System, dass alle notwendigen Buildschritte zusammenfasst / bündelt.
Das kann im einfachsten Fall ein Shell-Skript sein, dass die einzelnen Buildschritte bündelt. Mittelfristig kommt an aber um die Einführung eines richtigen Buildsystems wie cMake, Perforce Jam, Maven oder Gradle nicht herum.
Maven und Gradle können darüber hinaus auch noch weitere Tätigkeiten wie das Dependency Management und die Ausführung von Tests und Qualitätsanalysen übernehmen.
Testautomatisierung
Testautomatisierung ist ein SW-Entwicklungsprojekt!
Für die Testautomatisierung muss Code geschrieben werden, viel Code. Ergo ist eine Testautomatisierung ein SW-Entwicklungsprojekt.
Deshalb sollten die gleichen Maßstäbe an diese Software gestellt werden, wie an die Software under Test (SUT).
Versionierung der Sourcen, Einsatz von statischer Code-Analyse, Schreiben von UnitTests gehören zum guten Ton. Ein solches Entwicklungsprojekt sollte mit gutem Beispiel vorangehen.
Deployment ist nicht optional!
It ain’t got the jive, if the systems not live
Deployment bedeutet, die Software dorthin zu bringen, wo sie später zum Einsatz kommen soll.
In der Testautomatisierung ist dies der erste und wichtigste Schritt, weil nur auf dem aktuellsten SW-Stand durchgeführte Tests überhaupt eine Aussagekraft besitzen
Das Deployment kann auf unterschiedlichste Arten durchgeführt werden
- Upload via FTP
- Mounten eines Netzwerksshare
- Deplyoment in einen Laufzeitcontainer wie Glassfish / Tomcat / JBoss
Hebelwirkung durch höhere Sprachen
Der Einsatz der Programmiersprache für die Testautomatisierung ist entscheidend für den Erfolg. Man erzielt eine bessere Hebelwirkung, wenn der Testcode in einer höherern / abstrakteren Sprache als der Produktcode geschrieben wird.
Beispiele:
- Produkt: C/C++ native App – Testcode: Java mit JNI / JNA
- Produkt: Java-Portal – Testcode: Python mit selenium webdriver
Massiver Einsatz von Standard-Bibliotheken
Techniken wie FTP, Telnet, logging, Generierung von Reports sollten nicht von Hand implementiert werden. Es empfiehlt sich der Einsatz von Bibliotheken
Quick wins – Peer Review / Code Review einführen
4-Augen-Prinzip
Ein Code Review soll die Gefahr verringern, dass
- ein Feature nicht korrekt umgesetzt wurde
- das falsche Feature umgesetzt wurde
- Code eingecheckt wird, der den Build bricht
- Code eingecheckt wird, der neue Bugs enthält
Für ein Review gibt es prinzipiell zwei Strategien
Review vor dem Checkin (pre commit code review)
Review nach dem Checkin (post commit code reviews)
Vor- und Nachteile
| Review vor dem Checkin | Review nach dem Checkin | |
|---|---|---|
| Vorteile | Checkin bricht den Build seltener Weniger neue Bugs |
Häufigere Checkins Räumliche / zeitliche Unabhängigkeit des Reviewers |
| Nachteile | Reviewer wird in seiner Arbeit unterbrochen | Ungeprüfter Code im Repo Review-Vorgänge bleiben liegen, Regel notwendig, z.B. Review innerhalb von 48h |
Unabhängig von der Review-Strategie sollten aus Gründen der Nachverfolgbarkeit sowohl im Issue als auch in der Checkin-Beschreibung der Reviewer angegeben werden.
Testfallmanagementsystem
Da beim Aufbau einer EBQS nach und nach neue Kolleg:innnen ins Team kommen, kann es Sinn ergeben, die Verwaltung der Testfälle in ein Testfallmanagementsystems zu migrieren. Dies hat mehrere Vorteile:
- Striktere Aufteilung zwischen Erstellung und Durchführung der Testfälle
- Aufgabenteilung: Erfahrenere Kolleg:innen erstellen die Tests
- Es kann ein Testplan für jede Lieferung erstellt werden
- Ein Testlauf kann von mehreren Personen durchgeführt werden -> Parallelisierung
- Der Fortschritt der Testdurchführung kann überwacht werden
- Die Projektleitung kann sich jederzeit Überblick über den Stand verschaffen
- Die Testfälle können zu Testsuiten gruppiert werden
- Für sporadische DevDrops kann damit ein Subset der Tests ausgewählt werden (Fokus-Tests)
- Testfälle lassen sich aktivieren / deaktivieren / reviewen
- Es können Reports erstellt werden
Abschließende Gedanken
Der Aufbau einer EBQS ist ein enormes Unterfangen, gerade wenn sie in einem schon länger laufenden Projekt etabliert werden soll. Erfahrungsgemäß stellen sich dauerhafte Erfolge erst nach einem halben bis dreiviertel Jahr ein, auch wenn Quick Wins wie ein manueller Smoketest schon die größten Schmerzen lindern können. Man benötigt Fingerspitzengefühl wenn man Verhaltensmuster (if it compiles, ship it) aufbrechen will.
Die Tester müssen sich oft erst ihr “standing” bei den Entwicklern erarbeiten. Am Anfang empfinden viele Entwickler die Tester als Störenfriede oder Nestbeschmutzer, daher kann zu viel Akribie und Herumreiten auf trivialen Fehler (C- & D- Prio) kontraproduktiv wirken. Über Zeit entwickelt sich aber ein Teamgeist, da Fehler idealerweise so früh im Entwicklungszyklus gefunden werden können, dass dadurch Überstunden und Kopfschmerzen deutlich zurückgehen.
Buchtipps zum Thema
Lessons Learned in Software Testing: A Context-Driven Approach
How Google Tests Software: Help me test like Google