Table of Contents
Motivation
In diesem Artikel möchte ich euch den Einsatz von TDD schmackhaft machen. Es gibt viel zu viel schlechte Software und aus meiner Sicht hängt das zu großen Teilen daran, dass diese Software nicht genug getestet wurde. Auch wenn ein Großteil der Tests oft von dedizierten Testern gemacht wird, könnt ihr als Entwickler euren Beitrag leisten, indem ihr für eine gute Testabdeckung auf der untersten Ebene sorgt. Als unterste Ebene in der Software-Entwicklung spricht man oft über eine “Unit”. Der Begriff ist nicht exakt definiert, hier kann eine Klasse, ein Modul, aber auch eine einzelne Funktion gemeint sein. Nichtsdestotrotz sind Unit-Tests ein wirksames Mittel, um die intrinsische Software-Qualität zu steigern. Ein Weg wie Unit-Tests entstehen können ist TDD.
Was bedeutet TDD?
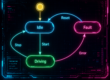
TDD steht für Test Driven Development, also test-getriebene Entwicklung. In einer perfekten Welt entsteht damit keine Zeile Produktiv-Code ohne einen korrespondieren Testfall.
Warum ist das gut? Aus mehreren Gründen. Bevor ihr den Code schreibt, macht ihr euch Gedanken über seine Verwendung, weil ihr im Test euren Code selbst aufrufen müsst.
Das führt dazu, dass man sich mehr Gedanken um die Schnittstelle und die Modularisierung machen muss, damit man überhaupt etwas testbares bekommt. (Weg vom Spaghetti-Code)
Dann implementiert man auch immer nur so viel Code, dass der Test erfolgreich durchläuft (Wir sagen “grün wird”)
Das korrespondiert sehr gut mit dem agilen Konzept der “Definition of Done”: Ich mache mir vor der Arbeit Gedanken darüber, wann die Arbeit erledigt ist.
Als Nächstes kann ich hemmungslos meinen Code refaktorn ohne mir Gedanken zu machen, ob ich ein einmal erfolgreich gebautes Feature wieder kaputtmache, weil mir die Tests unmittelbar verraten, wenn ich Mist mache.
Aber lassen wir den Worten doch Taten folgen:
Vorbereitung
Für dieses Beispiel benötigt ihr eine halbwegs aktuelle Python-Installation und einen Editor eurer Wahl.
Für TDD empfehle ich die Benutzung von pytest, da es weniger setup braucht, um erste Tests schreiben zu können und das Standardkommando auch das automatische Finden von Testfällen erleichtert.
pip install pytestUnser erster Test
Wir legen eine neue Datei test_mean.py an und fügen den ersten Testfall hinzu:
def test_mean():
assert False
Jetzt können wir pytest im Terminal starten, um sicherzugehen, dass der Test gefunden wird. pytest deutet alles was das Wort “test” im Namen hat als Test und versucht es auszuführen.
Struktur schaffen
Das Ziel der Übung soll sein, eine Funktion zu haben, die den Mittelwert einer Datenreihe berechnet.
Dazu schreiben wir das Grundgerüst der Funktion und rufen diese in unserem Test auf.
def test_mean():
assert calculate_mean([1]) == 1
def calculate_mean(data):
pass
Der Test ist jetzt noch rot. Das ist aber richtig und wichtig, weil wir sicherstellen müssen, dass unser Test auch wirklich unsere Implementierung testet.
Wäre er schon am Anfang grün, würden wir irgendetwas testen, nur nicht den Code, den wir ja jetzt eigentlich erst schreiben wollen.
Implementieren bis Test grün
Unsere Aufgabe ist es jetzt, den Test mit dem dümmst-möglichen Code auf grün zu bringen. In unserem Fall:
def calculate_mean(data):
return 1
Das ist so dumm, das tut schon fast weh. Aber: Fake it till you make it! Wir wissen, dass der Mittelwert einer Zahl sie selbst sein muss und deshalb ist der Code auch so korrekt.
Wenn wir pytest im Terminal ausführen, läuft der Test jetzt auch durch. Bingo!
Neuer Testcase
Wir wollen uns aber auch nicht zu lange ausruhen und wiederholen das Spiel mit folgendem Testfall:
def test_mean_2():
assert calculate_mean([2]) == 2
Wenn wir pytest ausführen, ist der Test auch wieder rot.
Implementieren bis Test grün
def calculate_mean(data):
return data[0]
Jetzt können wir beide Testfälle erfüllen, indem wir das erste Element der Liste (Achtung Index 0!) zurückgeben,
Neuer Testcase
Ein weiterer Fall mit einem Element würde keinen Erkenntnisgewinn bringen, deshalb übergeben wir jetzt eine Liste mit zwei Elementen:
def test_mean_two_elements():
assert calculate_mean([1, 2]) == 1.5
Implementieren bis Test grün
Jetzt müssen wir eine Fallunterscheidung machen: wenn die Länge der Datenreihe zwei ist, addieren wir die Werte an Index 0 und 1 und teilen sie durch zwei.
def calculate_mean(data):
if len(data) == 2:
return (data[0] + data[1]) / 2
return data[0]
Rule of Three
Jetzt haben wir den Punkt erreicht, an dem wir dreimal das gleich getan haben. Wir haben dreimal einen ähnlichen Testfall geschrieben und deshalb führen wir jetzt parametrisierte Tests ein. parametrize ist ein schönes pytest-Feature. Ihr definiert Eingangsdaten und Erwartungswert und der decorator @pytest.mark.parametrize sorgt dafür, dass euer Test so oft ausgeführt wird, wie Datenzeilen vorhanden sind. Ihr spart damit eine Menge Schreibarbeit!
import pytest
@pytest.mark.parametrize(
"data, expected_mean",
[
([1], 1),
([2], 2),
([1, 2], 1.5)
]
)
def test_mean(data, expected_mean):
assert calculate_mean(data) == expected_mean
Wenn ihr den Test startet, sollte der auch noch grün sein, da wir die drei einzelnen Testfälle durch den einen parametrisierten Test ersetzt haben.
Neuer Testcase
Jetzt haben wir die Grundlage, um entspannt einen neuen Testfall mit drei Eingangswerten zu ergänzen:
@pytest.mark.parametrize(
"data, expected_mean",
[
([1], 1),
([2], 2),
([1, 2], 1.5),
([1, 2, 3], 2),
]
)
Implementieren bis Test grün
Wir wiederholen das Spiel für den Fall mit drei Elementen: Überprüfen der Länge, Addieren der Elemente und Teilen durch drei.
def calculate_mean(data):
if len(data) == 2:
return (data[0] + data[1]) / 2
if len(data) == 3:
return (data[0] + data[1] + data[2]) / 3
return data[0]
Der Test sollte jetzt auch wieder grün sein.
Refactoring
Mit einem grünen Test können wir jetzt gefahrlos refactorn.
Die Implementierung aus Test 1 & 2 passen wir vom Aussehen an, damit es sich im nächsten Schritt generalisieren lassen kann.
def calculate_mean(data):
if len(data) == 1:
return data[0] / 1
if len(data) == 2:
return (data[0] + data[1]) / 2
if len(data) == 3:
return (data[0] + data[1] + data[2]) / 3
Rule of Three – die Zwote
Jetzt haben wir wieder einen Punkt erreicht, an dem wir wieder dreimal das gleich getan haben.
In diesem Fall haben wir dreimal eine ähnliche Implementierung geschrieben. Der Unterschied besteht hier in der Länge der Datenreihe.
Deshalb refactorn wir erstmal die len(data)-Aufrufe und ziehen eine Variable raus:
def calculate_mean(data):
length = len(data)
if length == 1:
return data[0] / 1
if length == 2:
return (data[0] + data[1]) / 2
if length == 3:
return (data[0] + data[1] + data[2]) / 3
Als Nächstes können wir den Teiler durch die length-Variable ersetzen:
def calculate_mean(data):
length = len(data)
if length == 1:
return data[0] / length
if length == 2:
return (data[0] + data[1]) / length
if length == 3:
return (data[0] + data[1] + data[2]) / length
Achtung: bitte immer nach jeder Änderung den Test / die Tests laufen lassen, damit wir frühzeitig herausfinden, ob wir etwas kaputtgemacht haben.
Jetzt geht es ans Eingemachte und es ist auch der größte Stretch: Wir müssen die Additionen loswerden. Dies können wir in einer Schleife machen. Wir benötigen eine Variable, die die Summe repräsentiert und am Anfang 0 ist. Dann addieren wir jedes Element aus unserer Datenreihe auf. Danach ersetzen wir die Additionen durch unsere neue Variable
if length == 3:
sum = 0
for elem in data:
sum = sum + elem
return sum / length
Die Tests laufen noch durch, also können wir weiter vereinfachen und die Abfragen für die unterschiedlichen Längen entfernen. Damit sieht unser Code nun so aus:
def calculate_mean(data):
length = len(data)
sum = 0
for elem in data:
sum = sum + elem
return sum / length
Das kann sich doch schon sehen lassen!
Just to be sure – neuer Testfall
Wir testen jetzt, ob unsere Generalisierung auch für den Fall mit 4 Elementen funktioniert und fügen noch
([1, 2, 3, 4], 2.5),
hinzu. pytest gestartet, läuft noch!
Corner Cases
Um eine robuste Implementierung zu bekommen, müssen wir noch den Fall “leere Liste” abhandeln. Also fügen wir noch den Testfall
([], None),
hinzu. Das heißt wir erwarten, dass die Funktion None zurückgibt, wenn eine leere Liste übergeben wird. Das frühstücken wir mit einem
if length == 0:
return
ab. Alternativ ließe sich natürlich auch eine Exception werfen.
Damit sind wir auch am Ende unserer kleinen TDD-Session.
Finale Worte
Dies ist ein Beispiel, wie sich TDD anwenden lässt. Die Anzahl der Zwischenschritte wirkt hier eventuell etwas künstlich hoch. Erfahrenere Entwickler würden wahrscheinlich dazu tendieren den Schritt mit der Summenberechnung direkt hinzuschreiben. Primär soll es aber darum gehen, die Abläufe im TDD zu üben (insbesondere die Rule of Three), daher ist die Implementierung die entstehen sollte bewusst einfach gewählt. Im Idealfall implementieren wir eine Mittelwertberechnung gar nicht selbst, sondern nutzen das statistics Modul.
Kompletter Code
import pytest
@pytest.mark.parametrize(
"data, expected_mean",
[
([], None),
([1], 1),
([2], 2),
([1, 2], 1.5),
([1, 2, 3], 2),
([1, 2, 3, 4], 2.5),
]
)
def test_mean(data, expected_mean):
assert calculate_mean(data) == expected_mean
def calculate_mean(data):
length = len(data)
if length == 0:
return
sum = 0
for elem in data:
sum = sum + elem
return sum / length