Table of Contents
Warum brauchen wir überhaupt KI?
Der Mensch ist im Grunde kein faules Tier. Er ist nur sehr konsequent darin, unnötige Mühen als persönliche Beleidigung zu empfinden.
Irgendwann stand also einer da, hatte zwei Arme voll Zeug und dachte: „Nee, komm, dat kann doch nich alles gewesen sein.“ Zack: Rad. Ein anderer kaute auf rohem Fleisch herum wie auf einem alten Fahrradmantel und kam zu dem Schluss, dass die Evolution ruhig mal einen Gang höher schalten könnte. Also Feuer.
Später saß jemand vor einem getippten Text und verschmierte Tipp-Ex. Daraus wurden dann Textverarbeitung, Backspace-Taste und dieses stille Glück, einen Fehler einfach verschwinden lassen zu können.
Im Kern geht es immer um dasselbe: Das Gehirn will nicht mehr Energie verbrauchen als unbedingt nötig. Es möchte rationale Entscheidungen treffen, Aufwand senken und den erwarteten Nutzen erhöhen. Klingt trocken, ist aber menschheitsgeschichtlich gesehen der rote Faden vom Faustkeil bis zur Tabellenkalkulation.
Und deshalb forscht der Mensch heute an KI: nicht nur, weil er bequem ist, sondern weil er verstehen will, wie Intelligenz funktioniert, wie man nützliche Aufgaben automatisiert und wie daraus Werkzeuge für Wissenschaft, Wirtschaft und Gesellschaft entstehen.
Kurz gesagt: Der Mensch denkt gern. Aber wenn eine Maschine das Vorsortieren übernehmen kann, sagt er auch nicht nein.
Historie der KI
„Ich baue ein Neuron so, dass es eine feste Regel ausführt.“
Die Sache mit der KI fing nicht erst an, als irgendein Start-up-Mensch mit Macha Latte in einem Co-Working-Space „disruptiv“ sagte.
Schon 1943 saßen Warren McCulloch und Walter Pitts da und dachten sich sinngemäß: „Wenn das Gehirn mit Neuronen arbeitet, kann man doch mal gucken, ob man sowas nicht auch in ordentlich nachbauen kann.“ Also beschrieben sie einfache Einheiten, die miteinander verknüpft werden – ein Netz, das grob an Nervenzellen im Gehirn erinnert. Das Paper hieß „A Logical Calculus of the Ideas Immanent in Nervous Activity“.
Das Neuron konnte als Boolesche Variable die Zustände wahr und falsch annehmen und „feuerte“ (= wahr), wenn die Summe der Eingangssignale einen Schwellenwert überschritt.
Und siehe da: Mit solchen künstlichen Neuronen ließen sich theoretisch so ziemlich jede logische oder arithmetische Funktion berechnen. Also alles, wofür normale Menschen später Taschenrechner, Computer und irgendwann Kaffee brauchten.
Das Perzeptron
„Ich gebe dem Neuron Beispiele, und es verändert seine Gewichte, bis es die Regel selbst gelernt hat.“
Dann kam das Perzeptron. Es wurde 1957 von Frank Rosenblatt vorgestellt und ist ein vereinfachtes künstliches neuronales Netz. Sein wichtigster Beitrag: die Anpassung der Gewichte erfolgte jetzt dynamisch. Die Ausgabe des Neurons blieb dank der Schwellwertfunktion aber digital 0 oder 1, auch wenn die Eingaben jetzt kontinuierliche Werte verarbeiten konnte.
Einlagiges Perzeptron
Nehmen wir ein Perzeptron mit 2 Eingaben und einer Ausgabe:
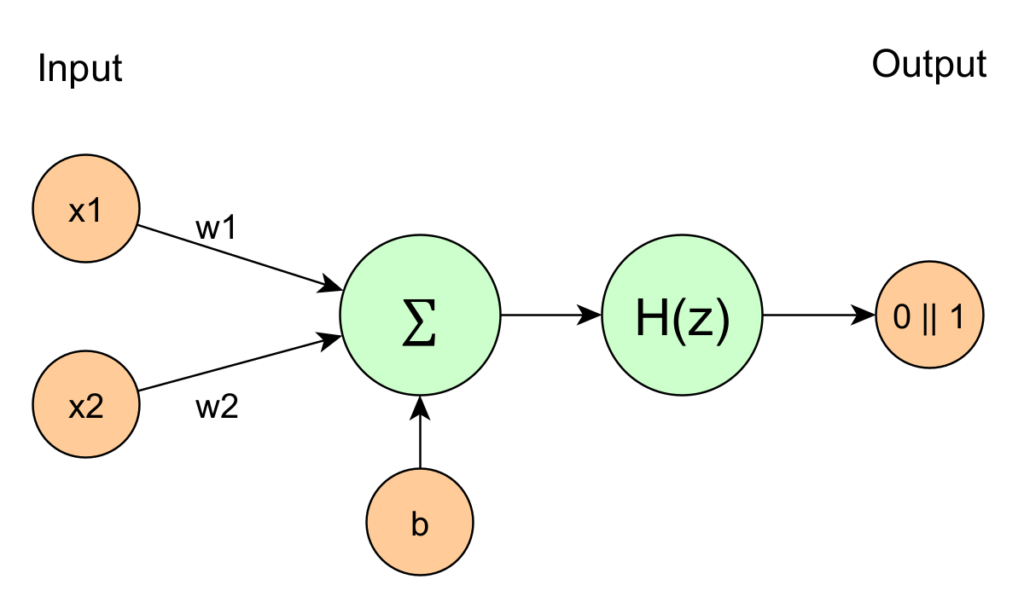
Die Verbindung vom Neuron x1 zu Neuron z wird mit dem Gewicht w1 multipliziert, die von x2 mit w2.
Zusätzlich wird noch ein unabhängiger Bias b addiert.
So kommt die Formel
zustande.
Jetzt Butter bei die Fische, wir rechnen jetzt mit konkreten Werten:
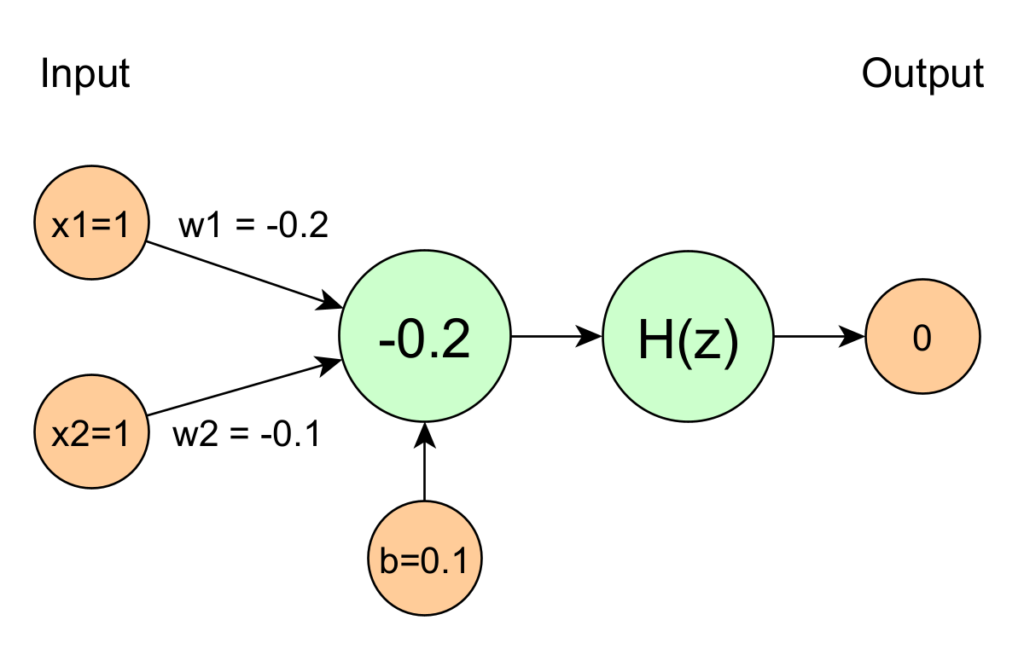
Eingabewerte
x_1 = 1 \\ x_2 = 1Gewichte
w_1 = -0.2 \\ w_2 = -0.1Bias
b = 0.1
Damit ergibt sich:
z = -0.2 * 1 + -0.1 * 1 + 0.1 = -0.2Aktivierungsfunktion
Jetzt kommt noch die Aktivierungsfunktion dazu.
Bei einem klassischen Perceptron verwendet man häufig eine Schwellenfunktion, auch Heaviside-Funktion oder Step Function genannt.
Das bedeutet: Liegt die gewichtete Summe über einem bestimmten Schwellwert, gibt das Neuron eine 1 aus. Liegt sie darunter, gibt es eine 0 aus.
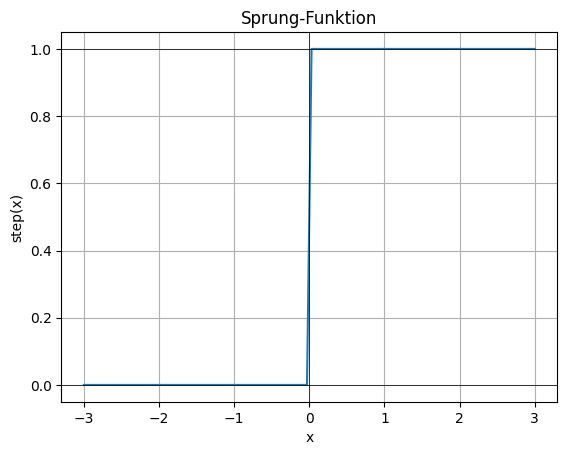
Da -0.2 kleiner als 0 ist, bleibt der Ausgang auch auf 0
y = H(z) = H(-0.2) = 0Error / Loss Function
Der Fehler ist die Differenz zwischen dem berechneten Wert und dem erwarteten Wert.
Beim Perceptron wird jetzt der Fehler berechnet, indem der Vorhersagewert vom echten Wert des Traininglabels abgezogen wird.
Für unser Beispiel erwarten wir eine 1 am Ausgang, bekommen aber eine 0, also ist der Fehler 1
error = 1 - 0 = 1Lernregeln und Lernrate
Konfuzius soll gesagt haben: „Ein Fehler, den man nicht korrigiert, ist der eigentliche Fehler.“
Beim Perzeptron gilt:
- Stimmen Ausgabe und Zielwert überein, bleiben Gewichte und Bias unverändert.
- Ist die Ausgabe 0, obwohl sie 1 sein sollte, werden die passenden Gewichte erhöht.
- Ist die Ausgabe 1, obwohl eine 0 erwartet wurde, werden sie verringert.
Mathematisch
w_i' = w + \Delta w \\
b' = b + \Delta b
Die Größe der Anpassung wird durch die Lernrate eta gesteuert:
\Delta w = \eta (y_{soll} - y_{ist}) * x_i \\
\Delta b = \eta (y_{soll} - y_{ist})
Nehmen wir eine Lernrate von:
\eta=0,1Dann werden die Gewichte angepasst:
w_1' = -0.2 + 0.1 (1-0) * 1 = -0.1 \\ w_2' = -0.1 + 0.1 (1-0) * 1 = 0.0Auch der Bias verändert sich:
b' = 0.1 + 0.1 (1-0) = 0.2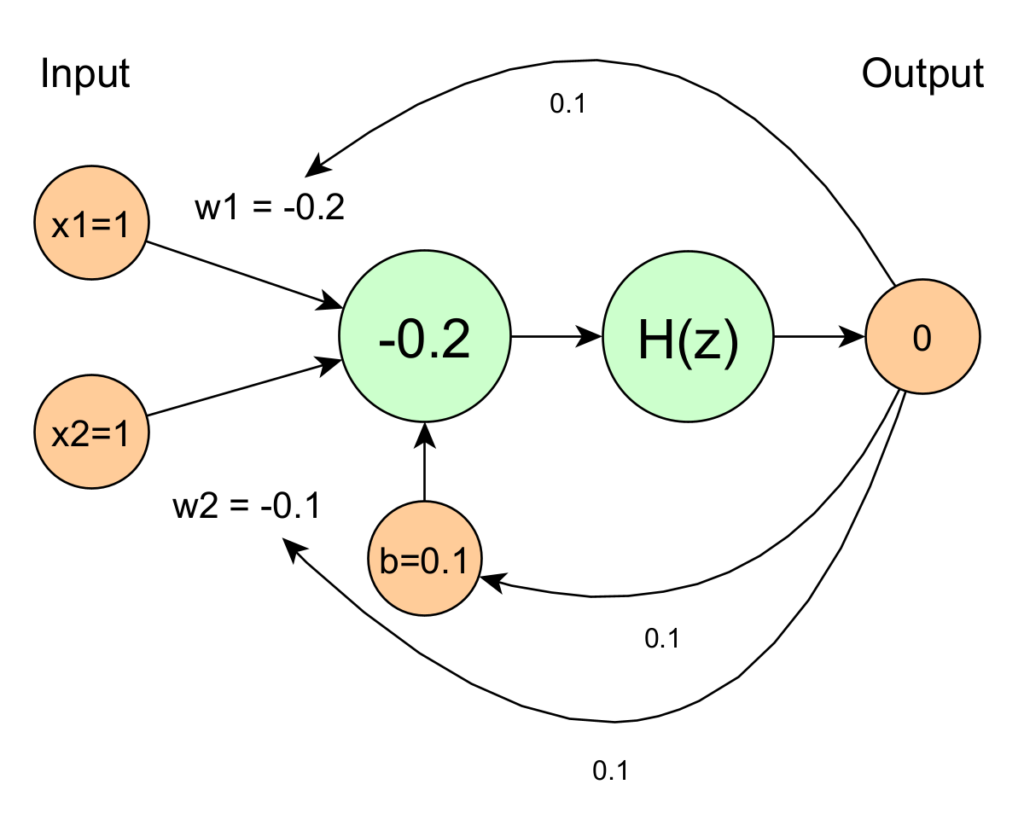 Mit den neuen Werten erhalten wir:
Mit den neuen Werten erhalten wir:
Nach der Aktivierungsfunktion:
y' = H(z') = 1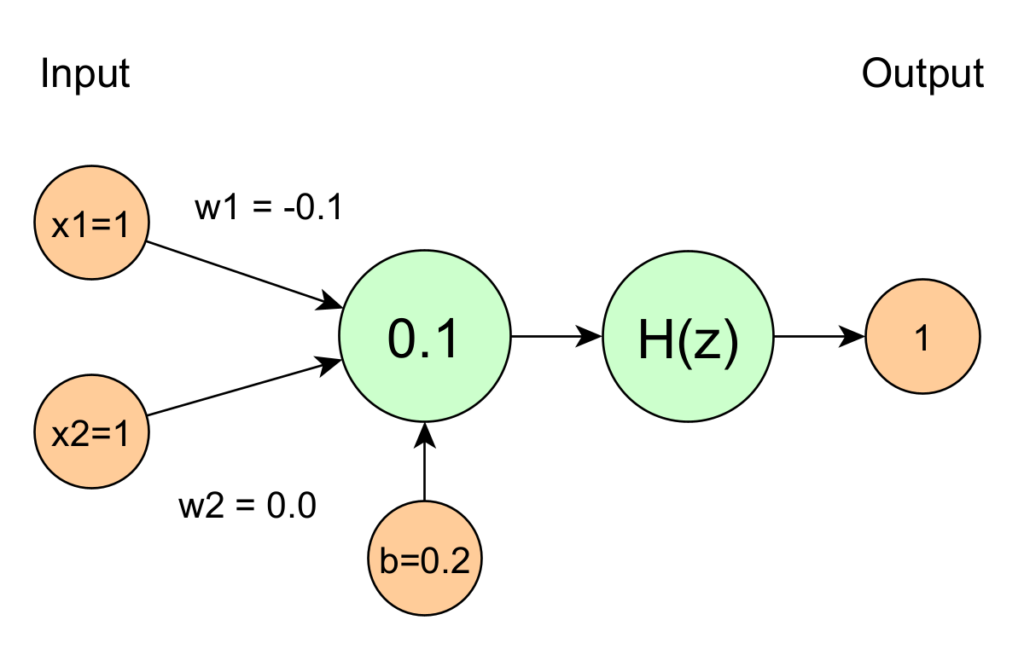 Nach nur einem Lernschritt liefert das Perzeptron den gewünschten Wert.
Nach nur einem Lernschritt liefert das Perzeptron den gewünschten Wert.
Epoche
In unserem Beispiel war bereits nach einer Anpassung das richtige Ergebnis erreicht. Das ist in der Praxis nicht immer so.
Häufig müssen sämtliche Trainingsbeispiele mehrfach verarbeitet werden, bis brauchbare Gewichte gefunden sind.
Einen vollständigen Durchlauf durch alle Trainingsdaten nennt man eine Epoche oder auf Englisch epoch.
Das klingt gewaltiger, als es ist. Im Grunde bedeutet es nur: einmal alles durchsehen und anschließend feststellen, dass man noch mal von vorne anfangen muss.
Beispiel: Festival-Entscheider
Schluss mit trockener Theorie, wir brauchen ein praktisches Anwendungsbeispiel!
Ich war auf Rock im Park mit einem Kumpel und das Lineup war gut und wir haben Camping-Tickets bekommen. Das Jahr drauf hat mir das Lineup nicht zugesagt und es waren keine Camping-Tickets verfügbar, also bin ich nicht gegangen.
Daraus können wir ein sehr einfaches Entscheidungsmodell bauen. Unser erster Eingang x1 beschreibt, ob mir das Line-up gefällt. Unser zweiter Eingang x2 beschreibt, ob ein Camping-Ticket verfügbar ist.
Eine 1 bedeutet „ja“, eine 0 bedeutet „nein“. Der Ausgang y beschreibt meine Entscheidung: Fahre ich hin, ist der Ausgang 1. Bleibe ich zu Hause, ist er 0.
| (x_1) Line-up | (x_2) Camping | (y) Entscheidung |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
Wir setzen das jetzt mit Python um. Ich verschone euch vorerst mit numpy, pytorch und Konsorten.
Für das Perzeptron reicht Vanilla Python völlig aus.
X = [
[0, 0],
[0, 1],
[1, 0],
[1, 1]
]
y_train = [0, 0, 0, 1]Die Gewichte und den Bias initialisieren wir jeweils mit 0:
weights = [0.0, 0.0]
bias = 0.0Als Lernrate nehmen wir wieder 0,1
eta = 0.1
number_of_epochs = 10Die Schwellenfunktion liefert 1, sobald z mindestens null ist:
def step_function(z):
return 1 if z >= 0 else 0Nun folgt das Training:
print(f"Start training: weights {weights}, bias {bias}")
for epoch in range(number_of_epochs):
for x, y_true in zip(X, y_train):
z = x[0] * weights[0] + x[1] * weights[1] + bias
y_pred = step_function(z)
error = y_true - y_pred
weights[0] = weights[0] + eta * error * x[0]
weights[1] = weights[1] + eta * error * x[1]
bias = bias + eta * error
print(f"Epoch {epoch} weights {weights}, bias {bias}")
print(f"Finished training: weights {weights}, bias {bias}")Das Programm geht alle Beispiele durch, berechnet eine Vorhersage und korrigiert bei Bedarf Gewichte und Bias.
Grenzen des Perzeptrons
Ein einzelnes Perzeptron kann nur Probleme lösen, die linear separierbar sind.
Das bedeutet: Die verschiedenen Klassen müssen sich durch eine gerade Linie, beziehungsweise in höheren Dimensionen durch eine Ebene, voneinander trennen lassen.
Unsere Festivalentscheidung funktioniert. Nur wenn sowohl Line-up als auch Camping stimmen, fahren wir hin. Diese Fälle lassen sich sauber trennen. Beim XOR-Gatter klappt das nicht. Für solche Probleme braucht man mehrere Schichten beziehungsweise komplexere neuronale Netze.
Ausblick auf das ADALINE
Das klassische Perzeptron lernt anhand der fertigen Entscheidung. Es sieht also nur die ausgegebene 0 oder 1.
ADALINE, kurz für Adaptive Linear Neuron, verwendet für das Lernen dagegen den linearen Rohwert vor der Schwellenfunktion.
Dadurch erkennt ADALINE nicht nur, ob eine Vorhersage falsch war, sondern auch, wie weit sie danebenlag.
Paper
https://www.cs.cmu.edu/~epxing/Class/10715/reading/McCulloch.and.Pitts.pdf
https://bpb-us-e2.wpmucdn.com/websites.umass.edu/dist/a/27637/files/2016/03/rosenblatt-1957.pdf
Links
https://neuralnetworksanddeeplearning.com/chap1.html
https://www.nutsvolts.com/magazine/article/the_perceptron_circuit
Videos
Hardware Perceptron
Perceptron Algorithm with Code Example
Adaline
Perceptron Research