In my article My personal road map for learning data science in 2018 I wrote about how I try to tackle the data science knowledge sphere. Due to the fact that 2018 is slowly coming to an end I think it is time for a little wrap up.
What are the things I learned about Data Science in 2018? Here we go:
Table of Contents
The difference between Data Science, Machine Learning, Deep Learning and AI
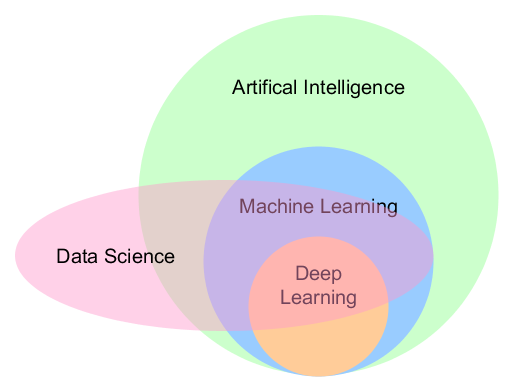
A picture says more than a thousand words.
The difference between supervised and unsupervised learning
Supervised Learning
You have training and test data with labels. Labels tell You to which e.g. class a certain data item belongs. Image you have images of pets and the labels are the name of the pets.
Unsupervised Learning
Your data doesn’t have labels. Your algorithm e.g. k-means clustering need to figure out a structure given only the data
The areas of applied machine learning
are described here: The Essence of Machine Learning and Data Science Overview
Bayes Theorem
In my article Bayes theorem I elaborated about the base rate fallacy and in naive bayes I recapped the second lesson from udacity’s UD120 Intro to Machine Learning
Precision and Recall and ROC
In my article classification: precision and recall I wrote about different useful measures to evaluate the quality of a supervised learning algorithm.
In Receiver Operating Characteristic I wrote about another useful measures the ROC.
Visualization with matplotlib
Matplotlib is a really good starting point for visualization. I wrote about it in Introduction to matplotlib, Matplotlib – Part 2, Scatterplot with matplotlib
Math with numpy
I wrote some articles about the usage of numpy but only scraped the surface of this mighty library
Image manipulation with OpenCV
JuPyter Notebooks
Sometimes I love them sometimes I hate them. I wrote an Introduction to JuPyter Notebook
Podcasts
In 2018 I’ve listened to a bunch of great podcasts on iTunes:





